3月29日,自然语言处理与认知计算团队(QLU-NLP)郑超群特聘副教授、李雅芳同学撰写的论文“From Incomplete to Valuable: Partial Cross-modal Hashing via Coarse-to-Fine Semantic Completion” 被IEEE Transactions on Multimedia录用。论文合作作者包括同济大学朱磊教授、齐鲁工业大学左瑞帆同学、新加坡国立大学王天一博士、悉尼科技大学李凤玲博士、齐鲁工业大学张维玉副教授,通讯作者为鹿文鹏教授。
IEEE Transactions on Multimedia(TMM)正式录用。TMM是中国计算机学会(CCF)推荐的A类国际期刊,在多媒体信息处理与智能分析领域具有重要学术影响力和广泛国际认可度。TMM由IEEE主办,长期致力于发表多媒体计算、跨模态理解、智能内容分析与生成、多媒体通信与系统等方向的高水平原创成果。作为多媒体领域的旗舰期刊之一,TMM以严格的审稿标准和高质量论文著称,是全球相关领域学者公认的顶级学术期刊。
题目:From Incomplete to Valuable: Partial Cross-modal Hashing via Coarse-to-Fine Semantic Completion
作者:郑超群、李雅芳、朱磊、左瑞帆、王天一、李凤玲、张维玉、鹿文鹏*
合作单位:同济大学、新加坡国立大学、悉尼科技大学
简介:现有的跨模态检索方法依赖于所有模态的完整且可访问的数据,以准确捕捉模态间的关联。然而,现实世界的数据集往往是不完整的,即使单个模态的缺失也会破坏这些关联,并显著降低检索性能。为解决这一挑战,我们提出了一种通过粗到细语义补全的缺失模态跨模态哈希方法(PCH-CFSC),专门用于具有挑战性的缺失模态跨模态检索场景。具体而言,我们设计了一个缺失模态补全网络,首先对不完整数据进行粗粒度填补以增强数据完整性,并建立基础的跨模态语义一致性。随后,我们引入基于跨模态Transformer架构的邻域语义引导细化网络,对数据进行进一步校准,从而更精准地解析多模态数据中的复杂语义关系。此外,我们结合关系图与对抗训练策略来学习哈希函数,确保生成的哈希码在不同模态间保持高度一致性并具备强判别能力。实验结果表明,我们的方法在缺失模态数据上展现出卓越性能,验证了其有效性与鲁棒性。
源代码地址:https://github.com/Lyf1590/PCH-CFSC
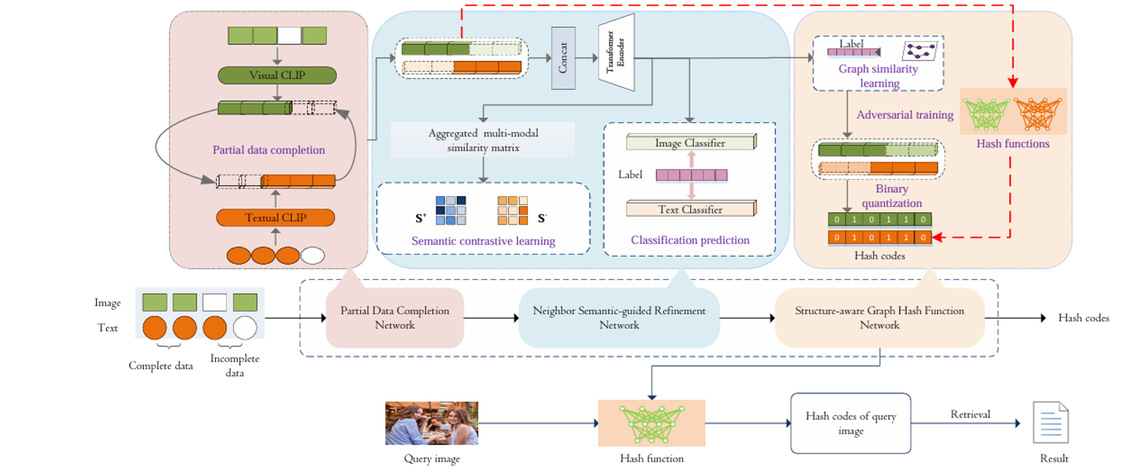
该论文是郑超群博士所主持的国家自然科学基金青年项目(面向隐私保护的联邦多模态检索方法研究,62502249)、山东省自然科学基金项目(面向模态缺失数据的深度跨模态哈希方法研究,ZR2024QF054)的重要学术成果,在信息检索上取得的新突破。李雅芳同学主要研究方向为缺失模态跨模态哈希检索,由郑超群博士指导,目前已发表CCF C类会议IJCNN一篇,现就职于山东协和学院。
论文引用形式:
Chaoqun Zheng, Yafang Li, Lei Zhu, Ruifan Zuo, Tianyi Wang, Fengling Li, Weiyu Zhang, Wenpeng Lu. From Incomplete to Valuable: Partial Cross-modal Hashing via Coarse-to-Fine Semantic Completion. IEEE Transactions on Multimedia[J]. 2026. (CCF A)